1.为什么需要工作流调度系统:
一个完整的数据分析系统通常由大量任务单元组成:shell脚本,java程序,mapreduce程序、hive脚本等
各任务单元之间存在时间先后及前后依赖关系
为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行;
例如,我们可能有这样一个需求,某个业务系统每天产生20G原始数据,我们每天都要对其进行处理,处理步骤如下所示:
1、 通过Hadoop先将原始数据同步到HDFS上;
2、 借助MapReduce计算框架对原始数据进行转换,生成的数据以分区表的形式存储到多张Hive表中;
3、 需要对Hive中多个表的数据进行JOIN处理,得到一个明细数据Hive大表;
4、 将明细数据进行复杂的统计分析,得到结果报表信息;
5、 需要将统计分析得到的结果数据同步到业务系统中,供业务调用使用。
2.工作流的调度方式:
简单的任务调度:直接使用linux的crontab来定义;
复杂的任务调度:开发调度平台或使用现成的开源调度系统,比如ooize、azkaban等
3.常见工作流调度系统:
目前有许多工作流调度器,在hadoop领域常见的工作流调度器有Oozie, Azkaban,Cascading,Hamake等
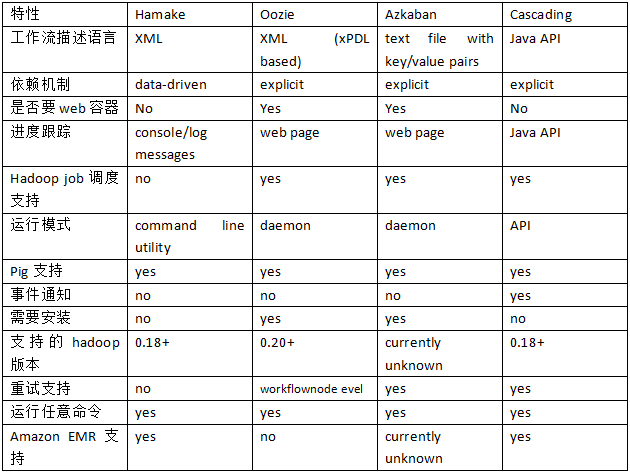
4.各种调度工具特性对比:
下面的表格对上述四种hadoop工作流调度器的关键特性进行了比较,尽管这些工作流调度器能够解决的需求场景基本一
致,但在设计理念,目标用户,应用场景等方面还是存在显著的区别,在做技术选型的时候,可以提供参考:
5.Azkaban与Oozie对比
对市面上最流行的两种调度器,给出以下详细对比,以供技术选型参考。总体来说,ooize相比azkaban是一个重量
级的任务调度系统,功能全面,但配置使用也更复杂。如果可以不在意某些功能的缺失,轻量级调度器azkaban是很不错
的候选对象。